Background
I’ve had the pleasure of working on a lot of different projects and while the language may have ranged from Java to Golang, most have communicated with a database using SQL. In the beginning of my career, I viewed SQL as a unfortunate neccessity, Professor Imilienski at Rutgers changed my opinion. His project and lectures showed us how to view the and analyze datasets in a relational database, and how SQL can be used to gather some pretty powerful insights. At the time, I used this new found knowledge to build Phillow, a web application that displayed the safety and quality of an area in Philly was based upon the publically available Philadelphia crime and school data. Now that I live in Raleigh, I thought it would be fun to look through Raleigh’s own crime data and hopefully reaffirm my decision to move down from PA.
Plan of action
I’m going to walk you through how to setup a Postgres docker container, load the Raleigh crime data into it, and then encourage you to write some queries to analyze the data. The answers to the query questions can be found below. One answer showing multiple methods of achieving the same results as well reviewing why the queries provide the same results but have different performance characteristics.
Requirements
- Download the dataset here: http://data-ral.opendata.arcgis.com/datasets/raleigh-police-incidents-nibrs
- Docker
- Experience with command line / SQL
Setup
Let’s startup the database and load the csv using the commands below:
docker run --name postgres -p 5432:5432 -d postgres # start the database in a docker container
docker cp Raleigh_Police_Incidents_NIBRS.csv postgres:/police_incidents.csv
// get psql shell
docker exec -it postgres psql -U postgres
CREATE TABLE raleigh_police_incidents (
OBJECTID int PRIMARY KEY,
GlobalID TEXT NOT NULL DEFAULT '',
case_number TEXT DEFAULT '',
crime_category TEXT,
crime_code varchar(5),
crime_description TEXT,
crime_type TEXT,
reported_block_address TEXT,
city_of_incident TEXT,
city TEXT,
district TEXT,
reported_date timestamp,
reported_year int,
reported_month int,
reported_day int,
reported_hour int,
reported_dayofwk TEXT,
latitude TEXT,
longitude TEXT,
agency TEXT,
updated_date timestamp
);
\copy raleigh_police_incidents FROM 'police_incidents.csv' WITH CSV HEADER DELIMITER E'\t';
Exploring the data
To familarize yourself with the data, try to find the following:
- Find how many incidents don’t possess a case number
- The number of distinct crime types
- Earliest reported_date in the data set.
- Crimes frequency by day of week
- Crimes that happen at night
- Crimes that happen during the day (8AM to 8 PM)
- The number of crimes in Raleigh per district in descending order
Answers to Exploring the Data
- 60515 with query:
SELECT COUNT(*) FROM raleigh_police_incidents WHERE case_number is null; - 3 not including the incidents without a specified crime_type
SELECT COUNT(*) FROM (SELECT DISTINCT crime_type FROM raleigh_police_incidents WHERE crime_type IS NOT NULL GROUP BY crime_type) crime_types; - 2014-06-1 04:15:00
SELECT MIN(reported_date) from raleigh_police_incidents ; -
SELECT COUNT(*), EXTRACT(DOW from reported_date ) as dayOfWeek FROM raleigh_police_incidents GROUP BY dayOfWeek;
count | dayofweek
-------+-----------
32011 | 0
35514 | 1
34620 | 2
34515 | 3
33850 | 4
34820 | 5
32900 | 6
- 129256
SELECT COUNT(*) FROM (select extract(hour from reported_date) as rhour from raleigh_police_incidents WHERE extract(hour from reported_date) > 7 AND extract(hour from reported_date) < 21) t; - 108974
SELECT COUNT(*) FROM (select extract(hour from reported_date) as rhour from raleigh_police_incidents WHERE extract(hour from reported_date) < 8 OR extract(hour from reported_date) > 20) t; SELECT COUNT(*), district FROM raleigh_police_incidents WHERE city ilike 'raleigh' GROUP BY district ORDER BY district DESC;Theilikeon city is neccessary due to not all city values being uppercaseRALEIGH.
count | district
-------+-----------
50755 | North
50204 | Southeast
40463 | Northeast
36195 | Southwest
33028 | Downtown
27256 | Northwest
245 |
(7 rows)
Query Plans and optimizations:
Consider the two queries:
SELECT COUNT(*), district FROM raleigh_police_incidents WHERE city ilike 'raleigh' GROUP BY district ORDER BY district DESC;SELECT COUNT(*), district FROM raleigh_police_incidents WHERE LOWER(city) = 'raleigh' GROUP BY district ORDER BY district DESC;
At a first glance I would have expected #2 to be most efficient since a standard approach to avoiding ilike is LOWER(columnName) like, but let’s look at the explain analyze results of the two queries below. For a quick primer on EXPLAIN ANALYZE check out the postgres resource here.
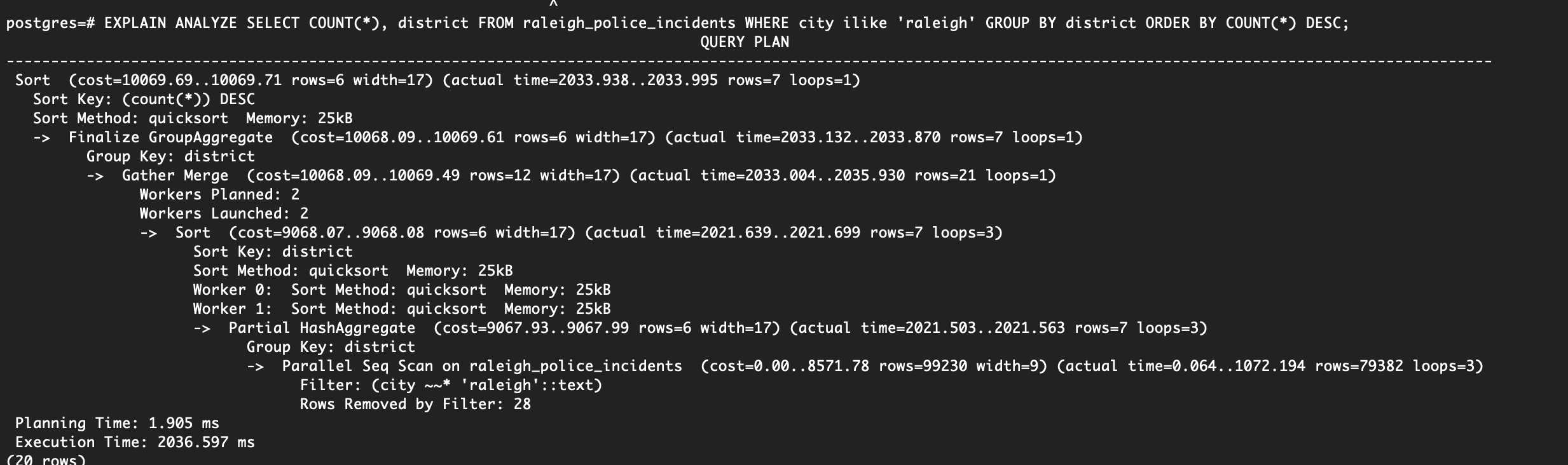

You should notice the following differences:
- The LOWER query is more expensive and consequently slower than the ILIKE query.
- The child plan node is very similar, but the LOWER query actually does a disk merge on the results, whereas the ILIKE query is able to keep the entire merge in memory.
- The child plan in the ILIKE query utilizes a PARTIAL HASHAGGREGATE for the GROUP BY, whereas the LOWER query uses a much slower sequential scan to finalize theq uery.
- While both queries return the same results, the ILIKE query is able to finish around 1000ms slower.
Recap
Having done a similar exercise for Philly, I have to say that Raleigh looks like a pretty safe city to me! I hope that you enjoyed looking through the crime data, found some useful insights, and brushed up on your SQL!
Helpful Resources: - https://thoughtbot.com/blog/reading-an-explain-analyze-query-plan - https://www.postgresql.org/docs/10/using-explain.html - https://www.postgresql.org/docs/11/planner-optimizer.html