This post builds upon the previous post. If you haven’t checked it out already, please do so here
In my opinion, SQL is easy to get working initially, but optimizing SQL is a whole different beast. Thankfully, I recently had the chance to optimize a whole bunch of SQL for one of our critical platforms resulting in an over 300% reduction in execution time. While I can’t promise the same result for anyone following this article, I do outline some of my learnings on optimizing for queries on text columns below using the most recent Raleigh Crime dataset.
The Query
Imagine a situation where we want to frequently see how many crimes have case insensitive keywords anywhere in the description which is the crime_description column in our table. For example, we want to find how many crimes have the term other in the crime description so we can start determining how many “uncommon” incidents occur in Raleigh.
To start, we create the following SQL:
SELECT * FROM raleigh_police_incidents WHERE crime_description ilike '%other%';

This works beautifully, however there is one easy performance tweak we can make. By using LOWER on the crime_description and changing the ilike to a like, we can usually achieve slightly better performance.
SELECT * FROM raleigh_police_incidents WHERE LOWER(crime_description) like '%other%';

Indexes
Indexes are a common way to enhance database performance. An index allows the database server to find and retrieve specific rows much faster than it could do without an index. But indexes also add overhead to the database system as a whole, so they should be used sensibly. - Postgres Documentation
If we do queries on the crime_description field frequently, it might make sense to add an index. For a quick primer on different index types, feel free to checkout the postgres documentation.
By default, Postgres will create a B-Tree index, let’s try that out and see what happens.
CREATE INDEX crime_description ON raleigh_police_incidents(crime_description);
Retrying the previous queries with EXPLAIN ANALYZE shows that absolutely nothing has changed. Reviewing the documentation shows us:
The optimizer can also use a B-tree index for queries involving the pattern matching operators LIKE and ~ if the pattern is a constant and is anchored to the beginning of the string — for example, col LIKE ‘foo%’ or col ~ ‘^foo’, but not col LIKE ‘%bar’. However, if your database does not use the C locale you will need to create the index with a special operator class to support indexing of pattern-matching queries; see Section 11.10 below. It is also possible to use B-tree indexes for ILIKE and ~*, but only if the pattern starts with non-alphabetic characters, i.e., characters that are not affected by upper/lower case conversion.
So it appears that the query speed wasn’t improved because we are using a wildcard at the beginning and end of our search term. Let’s see if there is any speed improvement by using a wildcard % just at the end of other like so:
EXPLAIN ANALYZE SELECT * FROM raleigh_police_incidents WHERE LOWER(crime_type) like 'other%';

Followed by DROP INDEX crime_description; and rerunning the same query shows . . . . Absolutely nothing has changed.
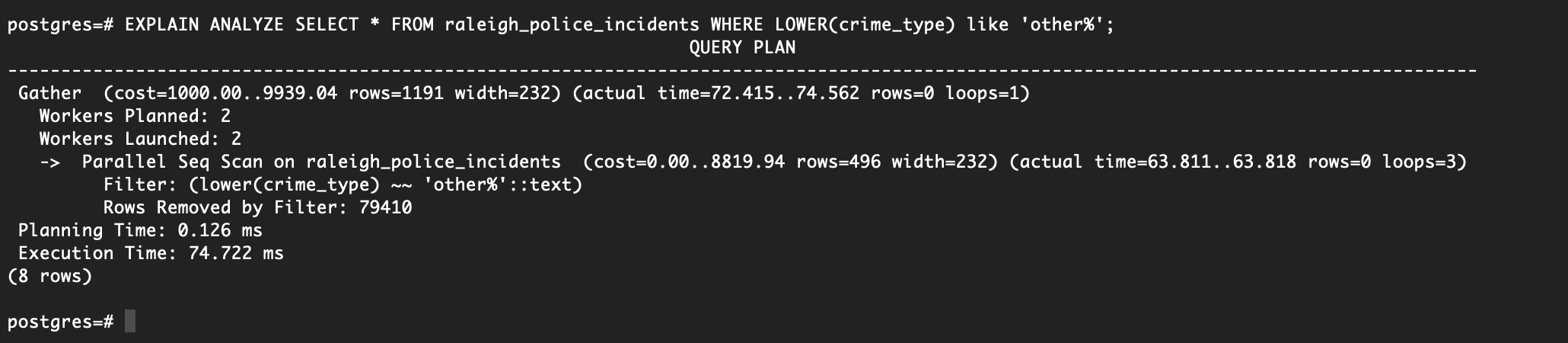
How dare Postgres not use our index!
While indexes can be very useful, they aren’t useful at all for our situation. One potential reason for this is that Postgres plans to visit most of the rows anyway, thus making it more effective to perform a parallel sequential scan. Either way, we could always force the planner to use our index by using: SET enable_seqscan = off, but beware that by doing so you walk a very dangerous path.
Solutions
So far, we’ve tried a few different potential solutions but haven’t really increased our query speed any significant amount. Let’s see what else we can do to optimize for our use case %${searchTerm}%.
- Alter how data is stored. If we find ourselves frequently querying the data for keywords, we could either add a keyword JSON array, start storing the keyword at the beginning of the text in order to benefit from a B-TREE index, or if possible use an additional column that can queried without the wildcard operator.
- Use the popular pg_trgm module to provide better performance for
like %${searchTerm}%queries. Specifically, this module provides GIN and GIST indexes which can be described as:
The pg_trgm module provides GiST and GIN index operator classes that allow you to create an index over a text column for the purpose of very fast similarity searches. These index types support the above-described similarity operators, and additionally support trigram-based index searches for LIKE, ILIKE, ~ and ~* queries. (These indexes do not support equality nor simple comparison operators, so you may need a regular B-tree index too.)
PG_TRGM
To show just how helpful pg_tgrm can be, let’s set it up and see the difference. Write CREATE EXTENSION pg_trgm; in psql to get started.
Next let’s create a GIN index, using:
CREATE INDEX crime_description_gin ON raleigh_police_incidents USING GIN (crime_description gin_trgm_ops);
SELECT * FROM raleigh_police_incidents WHERE LOWER(crime_type) like '%other%';
Looking at the picture below, you should notice that the query went from ~1500ms to ~75ms! A huge improvement and exactly what we are looking for!
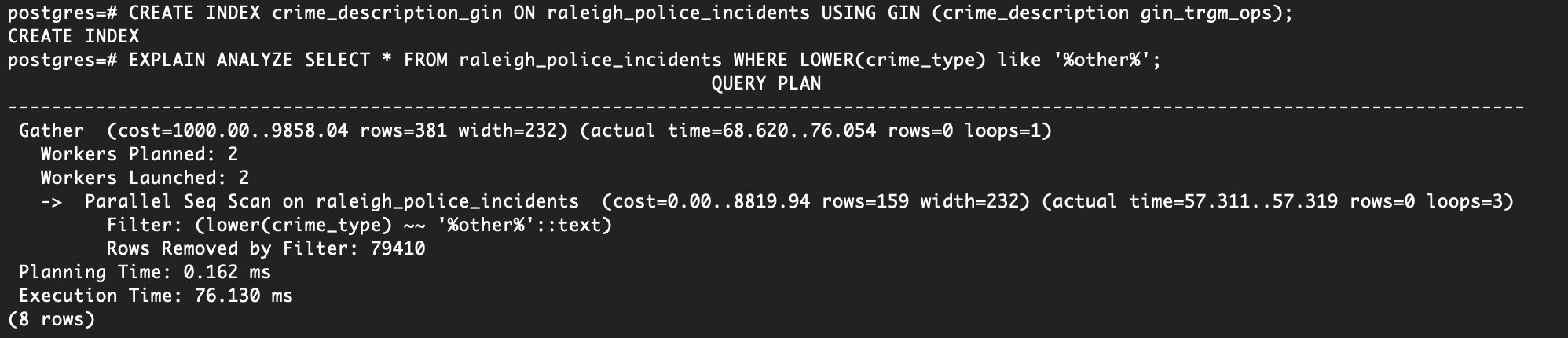
While pg_trgm is helpful for wildcard queries, it’s still important to use a B-Tree index if you plan on frequently querying the text column with equality or simple comparison operators as GIN indexes.
Future reading
If you want to read more about Postgres query plans or the different scanning methods available please checkout the following resources:
- https://stackoverflow.com/questions/13441334/when-to-add-an-index-on-a-sql-table-field-mysql
- https://www.postgresql.org/docs/11planner-optimizer.html
- https://severalnines.com/database-blog/overview-various-scan-methods-postgresql
- https://www.postgresql.org/docs/11/performance-tips.html
- https://dba.stackexchange.com/questions/119386/understanding-bitmap-heap-scan-and-bitmap-index-scan